データ基盤におけるエンジニア主導の低コストな自然言語処理パイプライン構築


社内でのデータ利活用が活発化していくにつれ、ビジネス・ユーザーにより扱うテキストデータへの感情分析など自然言語処理ニーズが増加。
従来は分析自動化のための自然言語処理パイプラインをサードパーティ製APIサービスで実現していたが、データ量に比例してAPI利用のコストも急増。
これがデータ利活用のスケールを阻害する要因となっていた。
内製モデルを活用したパイプラインの実現による自然言語処理のコストの大幅な削減。
AI・データそれぞれの専門性を持つエンジニアで構成された体制の構築とプロジェクトの完遂による連携強化。
DeNAでは多くのプロダクトを抱えており、あらゆる組織でデータ分析を活用してサービス改善に役立てています。
これらデータの収集・加工を担い、社内で適切かつ有効的に利活用できる状態を支えてきたデータ基盤部データエンジニアリンググループですが、ビジネスでのニーズに比例してデータ量の増加に伴い、利用していた自然言語処理を行うサードパーティ製APIサービスのコストがデータ活用を進めるための障壁の一因となっていました。
これを解決するために、データエンジニアが主体となりデータ本部に在籍するAI・MLOpsエンジニアによるプロジェクトを立ち上げ、各自の専門性を活かした開発体制と協力体制を構築することで効率的な自然言語処理パイプラインを実現し、課題であったコストを97%以上削減しました。
DeNA社内ではテキストデータから感情を分析する自然言語処理ニーズが多くありますが、サービスにかかるコストがネックとなり依頼できなかったというユーザーが存在しており、データ利活用における機会の損失が生じていました。
サードパーティ製の自然言語処理APIサービスに代わってモデル開発・サービスの内製化を実現したことにより、現在は97%以上費用負担を削減できています。
このように大幅にコストを抑制したことに加え、ユーザーのニーズにより応えることが可能となりました。
DeNAでは多数のAI・データのプロジェクトを担っているものの、データ本部が成り立つ以前は社内プロジェクトとしてAI人材・データ人材が協働する機会はあまり多くはありませんでした。
データ本部ではAI・データ両方の人材が1つとなることで、社内でのコミュニケーションが活発に行われています。
そうした環境において自然言語処理パイプライン内製化プロジェクトでの協働・成功をはじめ、様々なAI&データのコラボレーション施策が行われています。
データ活用のために大量に蓄積されていた既存の自然言語処理済み(感情分析)データを用いて、BERTをベースにファインチューニングによる推論モデルを準備しました。
自然言語処理パイプラインの開発前にPoCとして新モデルの準備および推論結果データを準備し、ユーザーへ実際のデータ分析ダッシュボードを活用したトライアルを実施しました。
従来のサードパーティ製APIサービスによる分析結果と精度が近く、かつ多くのビジネスユーザーから分析データへの違和感がなく実用出来ることが確認できました。と評価を頂いています。
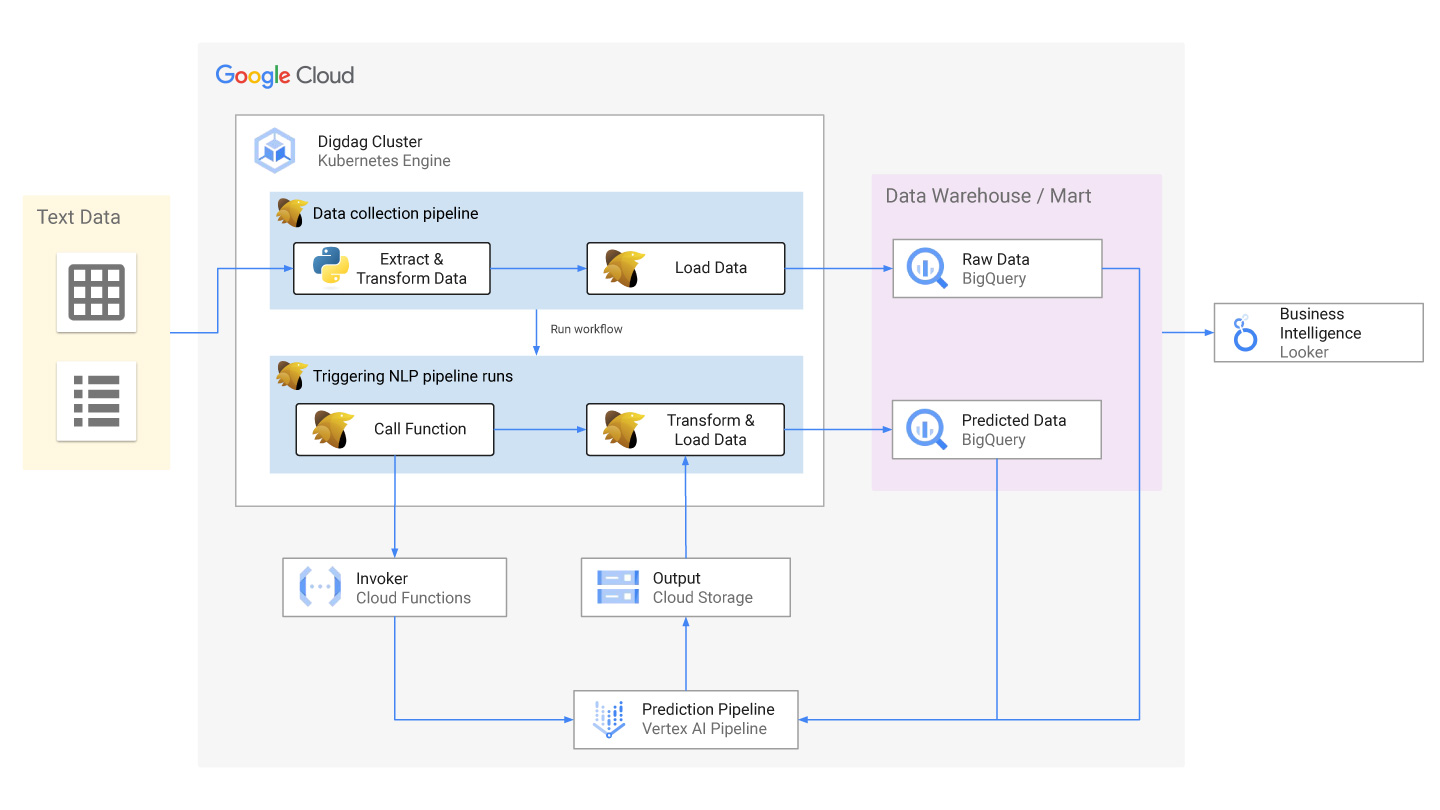
これまで利用していたサードパーティ製の自然言語処理APIサービスを、Google Cloud PlatformのサービスであるVertex AI Pipelineを用いたサーバレスな機械学習プラットフォームへ置き換えています。
Vertex AI Pipeline を機械学習プラットフォームの予測処理として利用することでインスタンスを構築するコストがなくなり予測処理に必要となるリソースのスケールアップ(CPU、GPU、メモリ)も必要量を適切に設定できコスト削減と実行時間の短縮にも繋がりました。
なお、ワークフローエンジンとしてdigdagを採択しており、自然言語処理の呼び出し機能の更新についてはVertex AI Pipelineにより出力される予測済みデータのインターフェイスに従来データとの互換性を持たせたことで大掛かりな開発を必要とせず、円滑なリプレイスを実現しています。